 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Detection In Aerial Images
Object detection in aerial images is the process of identifying and localizing objects in satellite or aerial images.
Papers and Code
Boundary and Position Information Mining for Aerial Small Object Detection
Jan 23, 2026Unmanned Aerial Vehicle (UAV) applications have become increasingly prevalent in aerial photography and object recognition. However, there are major challenges to accurately capturing small targets in object detection due to the imbalanced scale and the blurred edges. To address these issues, boundary and position information mining (BPIM) framework is proposed for capturing object edge and location cues. The proposed BPIM includes position information guidance (PIG) module for obtaining location information, boundary information guidance (BIG) module for extracting object edge, cross scale fusion (CSF) module for gradually assembling the shallow layer image feature, three feature fusion (TFF) module for progressively combining position and boundary information, and adaptive weight fusion (AWF) module for flexibly merging the deep layer semantic feature. Therefore, BPIM can integrate boundary, position, and scale information in image for small object detection using attention mechanisms and cross-scale feature fusion strategies. Furthermore, BPIM not only improves the discrimination of the contextual feature by adaptive weight fusion with boundary, but also enhances small object perceptions by cross-scale position fusion. On the VisDrone2021, DOTA1.0, and WiderPerson datasets, experimental results show the better performances of BPIM compared to the baseline Yolov5-P2, and obtains the promising performance in the state-of-the-art methods with comparable computation load.
D$^3$R-DETR: DETR with Dual-Domain Density Refinement for Tiny Object Detection in Aerial Images
Jan 06, 2026Detecting tiny objects plays a vital role in remote sensing intelligent interpretation, as these objects often carry critical information for downstream applications. However, due to the extremely limited pixel information and significant variations in object density, mainstream Transformer-based detectors often suffer from slow convergence and inaccurate query-object matching. To address these challenges, we propose D$^3$R-DETR, a novel DETR-based detector with Dual-Domain Density Refinement. By fusing spatial and frequency domain information, our method refines low-level feature maps and utilizes their rich details to predict more accurate object density map, thereby guiding the model to precisely localize tiny objects. Extensive experiments on the AI-TOD-v2 dataset demonstrate that D$^3$R-DETR outperforms existing state-of-the-art detectors for tiny object detection.
Remote Sensing Change Detection via Weak Temporal Supervision
Jan 05, 2026Semantic change detection in remote sensing aims to identify land cover changes between bi-temporal image pairs. Progress in this area has been limited by the scarcity of annotated datasets, as pixel-level annotation is costly and time-consuming. To address this, recent methods leverage synthetic data or generate artificial change pairs, but out-of-domain generalization remains limited. In this work, we introduce a weak temporal supervision strategy that leverages additional temporal observations of existing single-temporal datasets, without requiring any new annotations. Specifically, we extend single-date remote sensing datasets with new observations acquired at different times and train a change detection model by assuming that real bi-temporal pairs mostly contain no change, while pairing images from different locations to generate change examples. To handle the inherent noise in these weak labels, we employ an object-aware change map generation and an iterative refinement process. We validate our approach on extended versions of the FLAIR and IAILD aerial datasets, achieving strong zero-shot and low-data regime performance across different benchmarks. Lastly, we showcase results over large areas in France, highlighting the scalability potential of our method.
RoLID-11K: A Dashcam Dataset for Small-Object Roadside Litter Detection
Jan 01, 2026Roadside litter poses environmental, safety and economic challenges, yet current monitoring relies on labour-intensive surveys and public reporting, providing limited spatial coverage. Existing vision datasets for litter detection focus on street-level still images, aerial scenes or aquatic environments, and do not reflect the unique characteristics of dashcam footage, where litter appears extremely small, sparse and embedded in cluttered road-verge backgrounds. We introduce RoLID-11K, the first large-scale dataset for roadside litter detection from dashcams, comprising over 11k annotated images spanning diverse UK driving conditions and exhibiting pronounced long-tail and small-object distributions. We benchmark a broad spectrum of modern detectors, from accuracy-oriented transformer architectures to real-time YOLO models, and analyse their strengths and limitations on this challenging task. Our results show that while CO-DETR and related transformers achieve the best localisation accuracy, real-time models remain constrained by coarse feature hierarchies. RoLID-11K establishes a challenging benchmark for extreme small-object detection in dynamic driving scenes and aims to support the development of scalable, low-cost systems for roadside-litter monitoring. The dataset is available at https://github.com/xq141839/RoLID-11K.
MODA: The First Challenging Benchmark for Multispectral Object Detection in Aerial Images
Dec 10, 2025



Aerial object detection faces significant challenges in real-world scenarios, such as small objects and extensive background interference, which limit the performance of RGB-based detectors with insufficient discriminative information. Multispectral images (MSIs) capture additional spectral cues across multiple bands, offering a promising alternative. However, the lack of training data has been the primary bottleneck to exploiting the potential of MSIs. To address this gap, we introduce the first large-scale dataset for Multispectral Object Detection in Aerial images (MODA), which comprises 14,041 MSIs and 330,191 annotations across diverse, challenging scenarios, providing a comprehensive data foundation for this field. Furthermore, to overcome challenges inherent to aerial object detection using MSIs, we propose OSSDet, a framework that integrates spectral and spatial information with object-aware cues. OSSDet employs a cascaded spectral-spatial modulation structure to optimize target perception, aggregates spectrally related features by exploiting spectral similarities to reinforce intra-object correlations, and suppresses irrelevant background via object-aware masking. Moreover, cross-spectral attention further refines object-related representations under explicit object-aware guidance. Extensive experiments demonstrate that OSSDet outperforms existing methods with comparable parameters and efficiency.
ABBSPO: Adaptive Bounding Box Scaling and Symmetric Prior based Orientation Prediction for Detecting Aerial Image Objects
Dec 10, 2025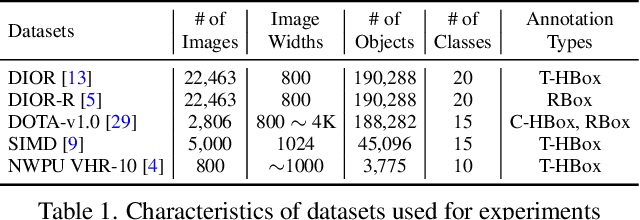
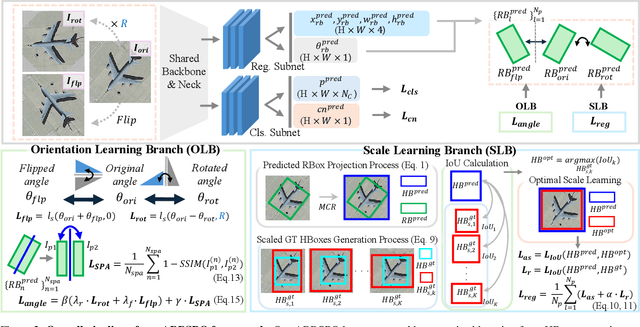
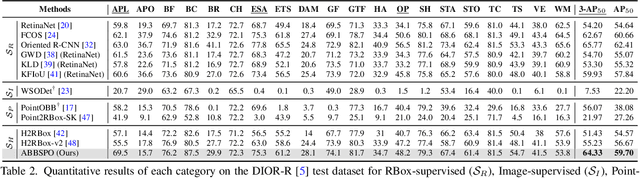
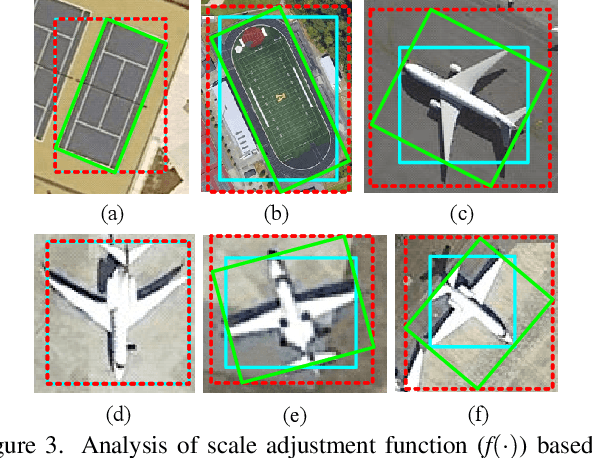
Weakly supervised oriented object detection (WS-OOD) has gained attention as a cost-effective alternative to fully supervised methods, providing both efficiency and high accuracy. Among weakly supervised approaches, horizontal bounding box (HBox)-supervised OOD stands out for its ability to directly leverage existing HBox annotations while achieving the highest accuracy under weak supervision settings. This paper introduces adaptive bounding box scaling and symmetry-prior-based orientation prediction, called ABBSPO, a framework for WS-OOD. Our ABBSPO addresses limitations of previous HBox-supervised OOD methods, which compare ground truth (GT) HBoxes directly with the minimum circumscribed rectangles of predicted RBoxes, often leading to inaccurate scale estimation. To overcome this, we propose: (i) Adaptive Bounding Box Scaling (ABBS), which appropriately scales GT HBoxes to optimize for the size of each predicted RBox, ensuring more accurate scale prediction; and (ii) a Symmetric Prior Angle (SPA) loss that exploits inherent symmetry of aerial objects for self-supervised learning, resolving issues in previous methods where learning collapses when predictions for all three augmented views (original, rotated, and flipped) are consistently incorrect. Extensive experimental results demonstrate that ABBSPO achieves state-of-the-art performance, outperforming existing methods.
Enhancing Small Object Detection with YOLO: A Novel Framework for Improved Accuracy and Efficiency
Dec 08, 2025This paper investigates and develops methods for detecting small objects in large-scale aerial images. Current approaches for detecting small objects in aerial images often involve image cropping and modifications to detector network architectures. Techniques such as sliding window cropping and architectural enhancements, including higher-resolution feature maps and attention mechanisms, are commonly employed. Given the growing importance of aerial imagery in various critical and industrial applications, the need for robust frameworks for small object detection becomes imperative. To address this need, we adopted the base SW-YOLO approach to enhance speed and accuracy in small object detection by refining cropping dimensions and overlap in sliding window usage and subsequently enhanced it through architectural modifications. we propose a novel model by modifying the base model architecture, including advanced feature extraction modules in the neck for feature map enhancement, integrating CBAM in the backbone to preserve spatial and channel information, and introducing a new head to boost small object detection accuracy. Finally, we compared our method with SAHI, one of the most powerful frameworks for processing large-scale images, and CZDet, which is also based on image cropping, achieving significant improvements in accuracy. The proposed model achieves significant accuracy gains on the VisDrone2019 dataset, outperforming baseline YOLOv5L detection by a substantial margin. Specifically, the final proposed model elevates the mAP .5.5 accuracy on the VisDrone2019 dataset from the base accuracy of 35.5 achieved by the YOLOv5L detector to 61.2. Notably, the accuracy of CZDet, which is another classic method applied to this dataset, is 58.36. This research demonstrates a significant improvement, achieving an increase in accuracy from 35.5 to 61.2.
Gaussian Process Assisted Meta-learning for Image Classification and Object Detection Models
Dec 23, 2025



Collecting operationally realistic data to inform machine learning models can be costly. Before collecting new data, it is helpful to understand where a model is deficient. For example, object detectors trained on images of rare objects may not be good at identification in poorly represented conditions. We offer a way of informing subsequent data acquisition to maximize model performance by leveraging the toolkit of computer experiments and metadata describing the circumstances under which the training data was collected (e.g., season, time of day, location). We do this by evaluating the learner as the training data is varied according to its metadata. A Gaussian process (GP) surrogate fit to that response surface can inform new data acquisitions. This meta-learning approach offers improvements to learner performance as compared to data with randomly selected metadata, which we illustrate on both classic learning examples, and on a motivating application involving the collection of aerial images in search of airplanes.
YolovN-CBi: A Lightweight and Efficient Architecture for Real-Time Detection of Small UAVs
Dec 19, 2025Unmanned Aerial Vehicles, commonly known as, drones pose increasing risks in civilian and defense settings, demanding accurate and real-time drone detection systems. However, detecting drones is challenging because of their small size, rapid movement, and low visual contrast. A modified architecture of YolovN called the YolovN-CBi is proposed that incorporates the Convolutional Block Attention Module (CBAM) and the Bidirectional Feature Pyramid Network (BiFPN) to improve sensitivity to small object detections. A curated training dataset consisting of 28K images is created with various flying objects and a local test dataset is collected with 2500 images consisting of very small drone objects. The proposed architecture is evaluated on four benchmark datasets, along with the local test dataset. The baseline Yolov5 and the proposed Yolov5-CBi architecture outperform newer Yolo versions, including Yolov8 and Yolov12, in the speed-accuracy trade-off for small object detection. Four other variants of the proposed CBi architecture are also proposed and evaluated, which vary in the placement and usage of CBAM and BiFPN. These variants are further distilled using knowledge distillation techniques for edge deployment, using a Yolov5m-CBi teacher and a Yolov5n-CBi student. The distilled model achieved a mA@P0.5:0.9 of 0.6573, representing a 6.51% improvement over the teacher's score of 0.6171, highlighting the effectiveness of the distillation process. The distilled model is 82.9% faster than the baseline model, making it more suitable for real-time drone detection. These findings highlight the effectiveness of the proposed CBi architecture, together with the distilled lightweight models in advancing efficient and accurate real-time detection of small UAVs.
Reliable Detection of Minute Targets in High-Resolution Aerial Imagery across Temporal Shifts
Dec 12, 2025Efficient crop detection via Unmanned Aerial Vehicles is critical for scaling precision agriculture, yet it remains challenging due to the small scale of targets and environmental variability. This paper addresses the detection of rice seedlings in paddy fields by leveraging a Faster R-CNN architecture initialized via transfer learning. To overcome the specific difficulties of detecting minute objects in high-resolution aerial imagery, we curate a significant UAV dataset for training and rigorously evaluate the model's generalization capabilities. Specifically, we validate performance across three distinct test sets acquired at different temporal intervals, thereby assessing robustness against varying imaging conditions. Our empirical results demonstrate that transfer learning not only facilitates the rapid convergence of object detection models in agricultural contexts but also yields consistent performance despite domain shifts in image acquisition.